Problem
The need to store user data safely is paramount, but traditional databases often struggle with ensuring both data privacy and the ability to efficiently make valid queries. As consumers and regulators demand more protection guarantees, it makes sense to explore new approaches to database design and outsourcing. To go down this path, clients would need verifiable results from their queries, while maintaining confidence that their data is secure and untampered.Solution
Our zkDB offers a powerful solution. By utilizing zero-knowledge proofs, it allows guarantees that the database includes all user data and hasn’t been tampered with; subsequent queries can be conducted in a provable and efficient manner.Key Properties
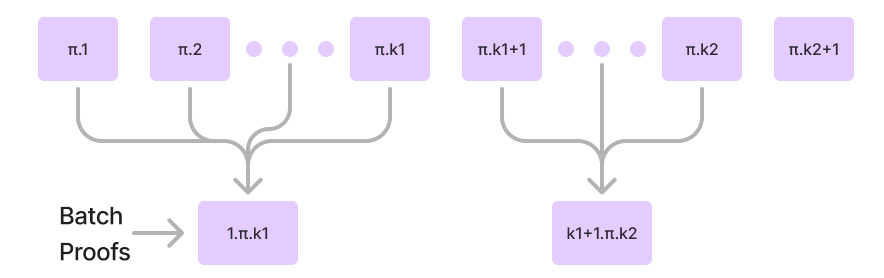
- Authenticated Data Structures (ADS): The database operates using an authenticated data structure with a single, updateable proof.
- Efficient Proofs: It is quick to check the validity of the entire database through that single proof, which can be updated as changes are made.
- Provable Queries: Clients can make queries and receive results that are provably correct and confirmed to come from the ADS.
- Data Protection: The zkDB prioritises user data protection, ensuring that private data is never exposed during query or update processes.
Architecture - ADS
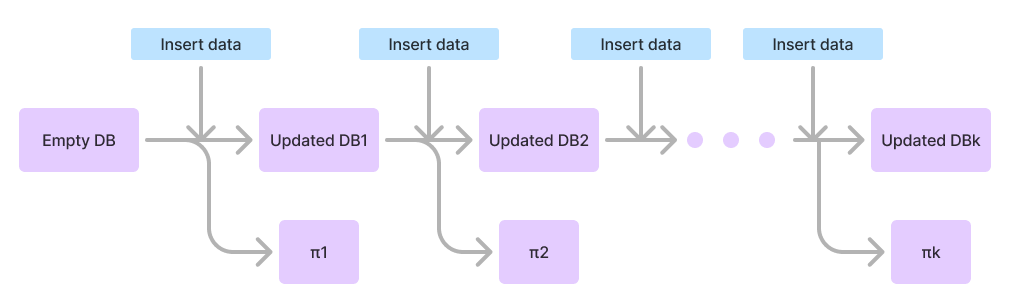
The architecture of the zkDB is built around a Merkle tree, and each update is tied to a proof that maintains the integrity of the entire database. Here’s an overview of the process:- Initialisation: The system begins with an empty Merkle tree that serves as the backbone of the zkDB.
- User Update: When a user updates their data, it is added to the Merkle tree.
- Proof Generation: After each update, the system generates a proof of the valid update.
- Repetition: The process is repeated with each new update, maintaining a continuous chain of actions with proofs of the validity of each.
Architecture - SQL
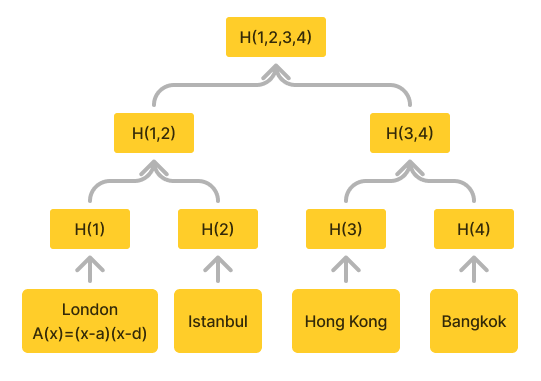
In order to allow efficient and provable queries, we have developed a SQL-like query language that is compatible with zero knowledge proofs, and that is compatible with our zkDB. We use bilinear accumulators to aggregate all addresses of users that have a particular property. We then put this accumulator in its own leaf of a Merkle tree, allowing us to grab it later when we need to know that all contained addresses will have that property. For example, below is an sketch of how we store data on the location of some users.